Method
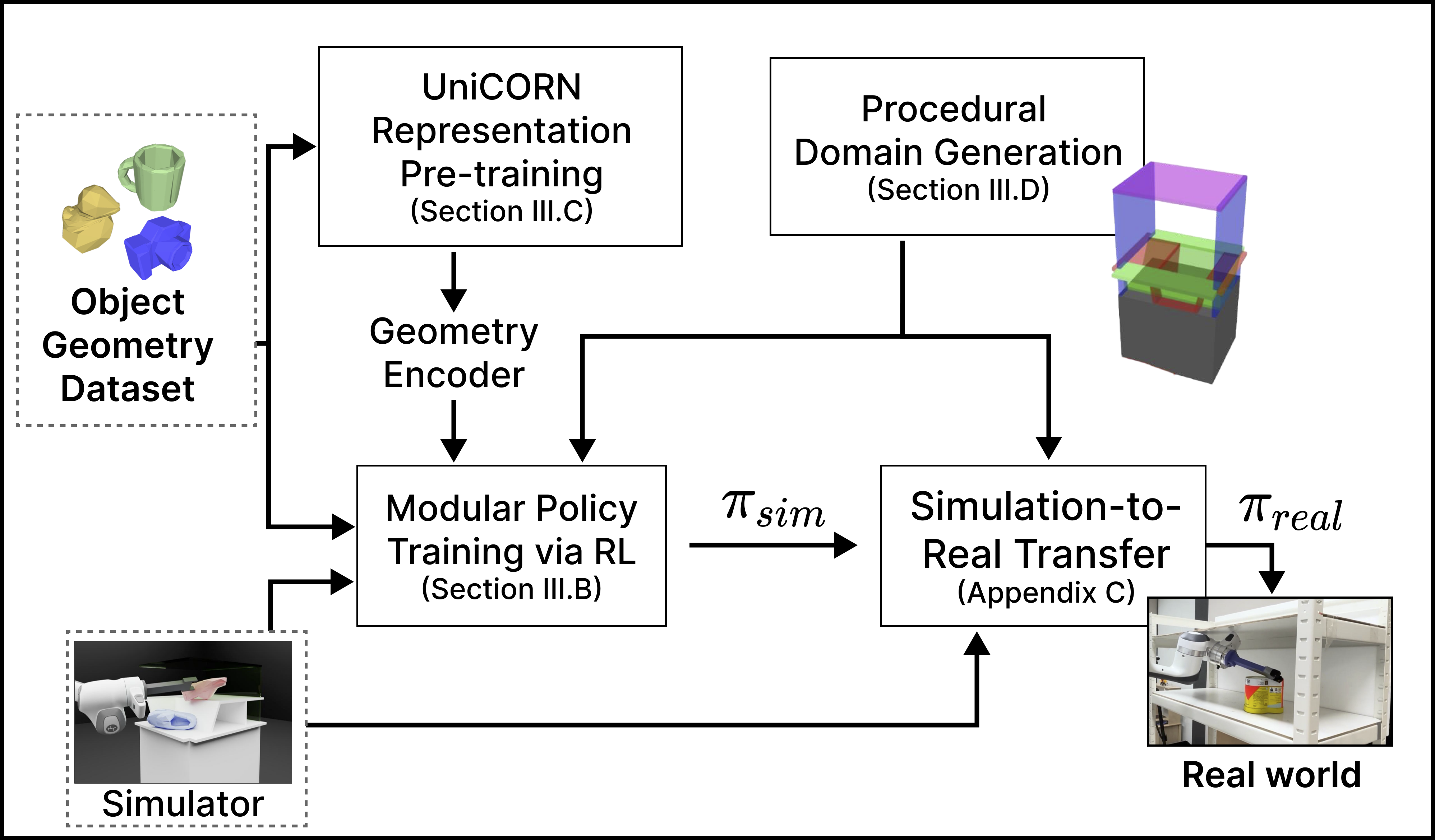
Our framework consists of four main components: a modular policy network architecture trained via RL, contact-based representation pre-training, a procedural domain generation scheme for environment geometries, and a simulation-to-real transfer method for real-world deployment.
Overall Architecture

Hierarchical And Modular Network (HAMNET)

HAMNet is a hierarchical architecture where the upper-level modulation network dynamically constructs the parameters of the lower-level base network. Based on the input context (robot, object, scene, and the goal), the modulation network (green) maps inputs to the base network's parameters θ by composing the modules and passing them through feature-wise gating. Conditioned on θ, the base network (blue) maps the state inputs and object geometry to actions and values.
Universal Contact-based Object Representation for Nonprehensile Manipulation (UniCORN)
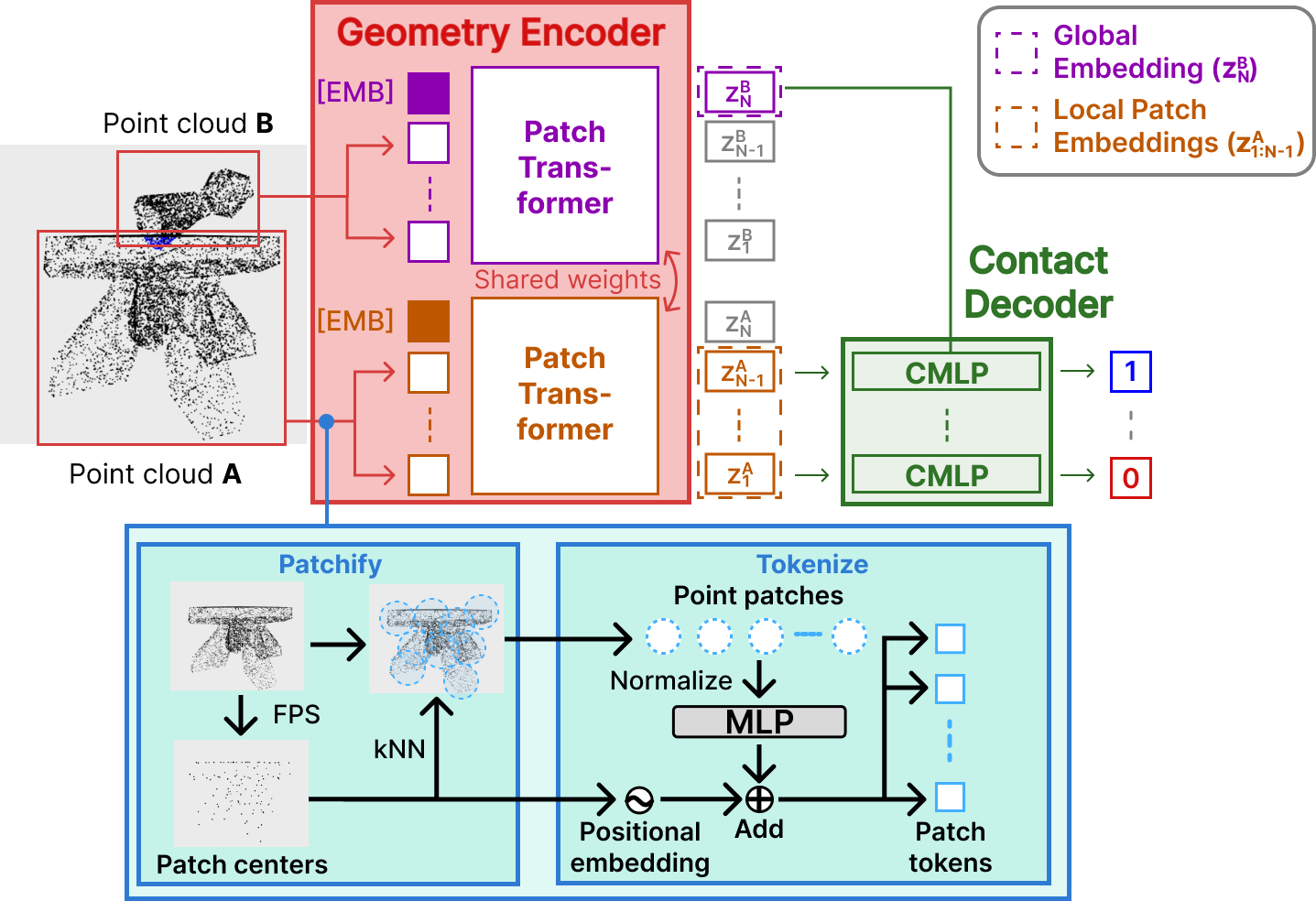
UniCORN is a geometry representation model that learns both local and global embeddings of geometries. During policy training, we use UniCORN as a lightweight and generalizable representation of object and environment geometries. During pretraining, UniCORN is used in a Siamese fashion to embed two point clouds A and B. Afterward, the contact decoder predicts contact between each local patch of A and the global embedding of B. The bottom block illustrates the patchification and tokenization process.
Procedural Domain Generation
We leverage procedural generation to construct diverse environment geometries during our simulation-based policy training. Our pipeline composes different environmental factors, such as walls, ceilings, and plates at different elevations for each axis, to construct geometrically diverse environments. This results in scenes that include real-world-like structures, such as cabinets, baskets, sinks, valleys, countertops, and steps.

{kind=link}